March 27, 2019 monitoring prometheus beginner introduction kubernetes
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. It is now a standalone open source project and is maintained independently of any company. To emphasize this, and to clarify the project’s governance structure, Prometheus joined the Cloud Native Computing Foundation in 2016 as the second hosted project, after Kubernetes.
A brief introduction to Prometheus
When working with Prometheus it is important to understand some of the differences, new features and new jargons that it brings to the table. In particular, we will be discussing the following:
Push vs Pull model
Unlike the traditional push methods where a monitoring agent would collect the metrics and will push to a centralized Monitoring server. Prometheus uses exporters that collect the system metrics and expose them at a defined endpoint from where the Prometheus server scrape or pulls the metrics.
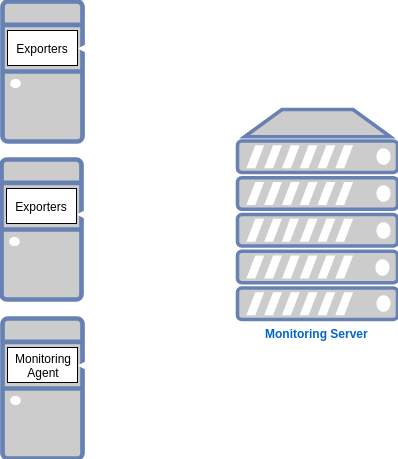
Exporters
The exporters are responsible for collecting and exposing Prometheus metrics for third-party or uninstrumented services. It resembles the monitoring agents in the traditional Push model.
Alertmanager
Prometheus itself is only responsible for monitoring, and features such as alerting, visualization, data storage is managed by separate and independent components providing a totally modular design.
Prometheus evaluates the alerting rules as per the metrics data collected and send alerts to Alertmanager in case of a violation.
Alertmanager then accordingly group, and categorize them as per the defined rules, and send the alert notification to the different notification channels configured such as slack, hipchat, email, pager duty, etc.
Time Series
A time series is a series of data points indexed (or listed or graphed) in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time.
- https://en.wikipedia.org/wiki/Time_series
Deploying Prometheus
- As a Kubernetes deployment in the cluster
- As a Kubernetes operator
We assume that you already have a running Kubernetes cluster. If not, go ahead and create one a small one now that you can use to follow along.
Deploying Prometheus: As a Kubernetes deployment in the cluster
We will be using the Helm charts for Prometheus located at https://github.com/kubernetes/charts for this example.
-
Clone the repo:
git clone https://github.com/kubernetes/charts -
Modify
stable/prometheus/values.yamlfile as per your needs. A recommended production configuration would be to choose a high-performance storage class configured on your cluster forstorageClass:and to have storage bigger than the 2Gi that is defined just above thestorageClassundersize: -
Once done, deploy it using:
helm install -f values.yaml stable/prometheus --name prometheus --namespace monitoringThis will apply thevalues.yamlfile to the stable Prometheus chart maintained by the Kubernetes project and will deploy it using Helm. -
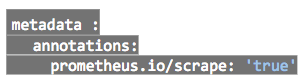
To let Prometheus scrape and monitor your services modify them to include:
-
Using above annotation Prometheus will autodiscover all of your services and will start monitoring them by scrapping the metrics.
-
Now edit
stable/grafana/values.yamland change the values ofadminPassword,size, andstorageClassto your liking. -
Now, search for
urland enter the Prometheus service endpoint. -
Once done, install Grafana using:
helm install -f values.yaml stable/grafana --name grafana --namespace monitoring
After the Grafana has been successfully deployed we will need to add Prometheus as a data source to Grafana. Steps for the same are listed below:
- To access the Grafana UI port forward the pod’s exposed port to a local port using:
kubectl port-forward <name-of-grafana-pod> -n monitoring <local-port-number>:3000 - Login to the Grafana UI by pointing your browser at
localhost:_<local-port-number>_and enter your admin name and password. - Now click on
Create your first data sourceand fill in the required values as below:
Name: A name to identify the data source
Type: Prometheus
URL: http://<prometheus-service-name>.monitoring.svc.cluster.local
- Leave rest of the fields to the default value and click on
Add.
Your Prometheus setup should now be successfully added to Grafana. You can now browse and add various dashboards to see the metrics gathered from Prometheus. Some of the common pre-configured dashboards can be found at: https://grafana.com/dashboards.
Deploying Prometheus: As a Kubernetes Operator
Apart from being deployed as a dedicated Kubernetes resource, Prometheus can also be deployed as a Kubernetes Operator. Using the Prometheus Operator we can natively and easily monitor the Kubernetes resources apart from managing Prometheus, Alertmanager and Grafana configuration.
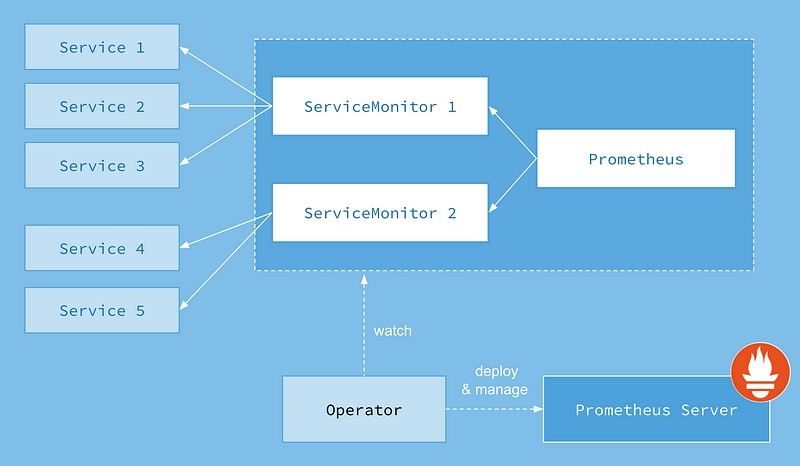
ServiceMonitor
Prometheus Operator uses a Custom Resource Definition (CRD), called ServiceMonitor, to manage the configuration. The ServiceMonitor will use the matchLabels selector to choose the resources to monitor and the Prometheus Operator will be using the label selectors to search for the resources after which it will create a Prometheus target so that Prometheus can scrape the resources for the metrics.
Steps to deploy Prometheus Operator:
- Add the CoreOS repo to helm:
helm repo add coreos https://s3-eu-west-1.amazonaws.com/coreos-charts/stable/ - Install the Prometheus Operator:
helm install coreos/prometheus-operator --name prometheus-operator --namespace monitoring - Install Prometheus Operator, Prometheus, Grafana, Alertmanager, and Node Exporters will be installed on your Kubernetes cluster with a sane default configuration provided by kube-prometheus:
helm install coreos/kube-prometheus --name prometheus-suite --namespace monitoring
Now you can view Grafana and Prometheus using their services prometheus-suite-grafana and prometheus-suite respectively.